Welcome to CleverMiner’s documentation!
Last updated: Mar 16, 2025
Project CleverMiner is Enhanced Association Rule Mining (eARM) package. It is based on GUHA procedures and rules are more general then in frequent itemset mining as well as arules package.
The advantages of CleverMiner and enchanced association rules are
rules are TRULY interpretable. Even in that way that can be used in work procedures that is operated by humans,
data preparation and handling is in common data science language - Python,
results are in machine processable form and API functions for further processing is available,
contains several new procedures like UIC-Miner,
new algorithms/workflows built on CleverMiner are available (like parameter free mining, clustering of association rules, …).
Note that interpretable methods are now considered as a part of explainable AI (XAI). CleverMiner contains several mining procedures that allows to solve different business questions via mining several pattern types.
Example of pattern type is If A then B with probability p. Having dataset Accidents (Kaggle dataset about UK Accidents, see Section Loading and preparing categorical data where complete example of data load and preparation can be found), we may be interested in more severe accidents. The distribution of accidents in entire dataset is shown below.
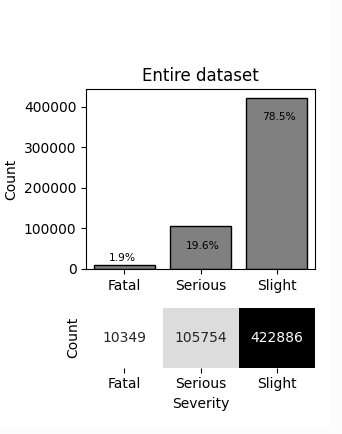
Severity |
Occurence |
Cummulative |
|---|---|---|
Fatal |
1.9% |
1.9% |
Serious |
19.6% |
21.5% |
Slight |
78.5% |
100.0% |
We can mine for circumstances (A in “If A then S with probability p”) under which severity of accidents is higher. Combined probability of Serious and Fatal severity (denoted as S or Severity(Serious,Fatal)) is 1.9%+19.6%=21.5%. We may mine for circumstances where the probability is higher.
Example of the rule that can be mined is Driver_Age_Band(46 - 55) & Speed_limit(50 60) & Sex(Male) => Severity(Fatal Serious) with probability (confidence) 33.3% and Base 2934. That means that the accident is Fatal or Serious in 32.8% cases for Male drivers that are 46-55 years old on a speed limit 50 to 60 (compared to 21.5% on entire dataset).
That means +55% increase (=33.3%/21.5%) of probability of S compared to the entire dataset.
Compared to apriori, where frequent itemset is used, CleverMiner method uses complete data matrix with categorized data. All continuous data should be converted to categorical ones. Cleverminer supports both nominal (unordered) and ordinal (ordered) categorial attributes. In previous example, Driver_Age_Band, Speed_limit and Severity was treated as ordinal variables.
Theory and detailed description of methods are in literature, e.g. here.
Installation
CleverMiner is a Python package. It assumes that you are familiar with Python. Package can run on Python 3.8+, but version 3.10+ is strongly recommended due to performance (new functions in Python 3.10 are utilized).
Installation is very easy. Cleverminer is packaged at pipy (PYthon Package Index), so installation is
pip install cleverminer
If you have already package installed and you need upgrade to newest version, use
pip install cleverminer --upgrade
Quick tutorial
This section makes quick introduction to several GUHA procedures and show simple examples of tasks than can be solved by CleverMiner.
In our example, we will use Accidents dataset (for details see Loading and preparing categorical data ). Our question will be for which group of drivers, circumstances etc. occur more Fatal accidents?
We will look for rules of type Driver_Age_Band(?) & Speed_Limit(?) & Sex(?) => Severity(Fatal) with probability at least 50% higher (x1.5) than in entire dataset and that is valid for at least 2000 cases.
Therefore we will set quantifiers as Base:2000 (valid for at least 2000 cases) and `aad:0.4`(at least 0.5 times higher probability).
Let do the first easy example. We will take a single value of Driver_Age_Band, Speed_Limit and Sex on the left hand side of the rule. We will use a simple notation (Available from version 1.2.1) clm_vars(['Driver_Age_Band', 'Sex', 'Speed_limit']).
On the right-hand side, we will use the single leftmost category from the Severity, i.e. Fatal. The code follows.
1import pandas as pd
2import sys
3
4from sklearn.impute import SimpleImputer
5from cleverminer import *
6
7# read the data
8df = pd.read_csv('https://www.cleverminer.org/data/accidents.zip', encoding='cp1250', sep='\t')
9df = df[['Driver_Age_Band', 'Sex', 'Speed_limit', 'Severity']]
10
11# handle missing values
12imputer = SimpleImputer(strategy="most_frequent")
13df = pd.DataFrame(imputer.fit_transform(df), columns=df.columns)
14
15clm = cleverminer(df=df, proc='4ftMiner',
16 quantifiers={'Base': 2000, 'aad': 0.5},
17 ante = clm_vars(['Driver_Age_Band', 'Sex', 'Speed_limit']),
18 succ = { 'attributes': [clm_lcut('Severity')],'minlen': 1, 'maxlen': 1, 'type': 'con'})
19
20clm.print_summary()
21clm.print_rulelist()
22clm.print_rule(2)
23clm.draw_rule(2)
This example gives us following results
Done. Total verifications : 72, rules 3, times: prep 0.41sec, processing 0.09sec
CleverMiner task processing summary:
Task type : 4ftMiner
Number of verifications : 72
Number of rules : 3
Total time needed : 00h 00m 00s
Time of data preparation : 00h 00m 00s
Time of rule mining : 00h 00m 00s
List of rules:
RULEID BASE CONF AAD Rule
1 2517 0.328 +0.522 Driver_Age_Band(46 - 55) & Sex(Male) & Speed_limit(60) => Severity(Fatal Serious) | ---
2 2598 0.036 +0.896 Sex(Male) & Speed_limit(60) => Severity(Fatal) | ---
3 3064 0.030 +0.583 Speed_limit(60) => Severity(Fatal) | ---
Rule id : 2
Base : 2598 Relative base : 0.005 CONF : 0.036 AAD : +0.896 BAD : -0.896
Cedents:
antecedent : Sex(Male) & Speed_limit(60)
succcedent : Severity(Fatal)
condition : ---
Fourfold table
| S | ¬S |
----|-----|-----|
A | 2598|68775|
----|-----|-----|
¬A | 7751|459865|
----|-----|-----|
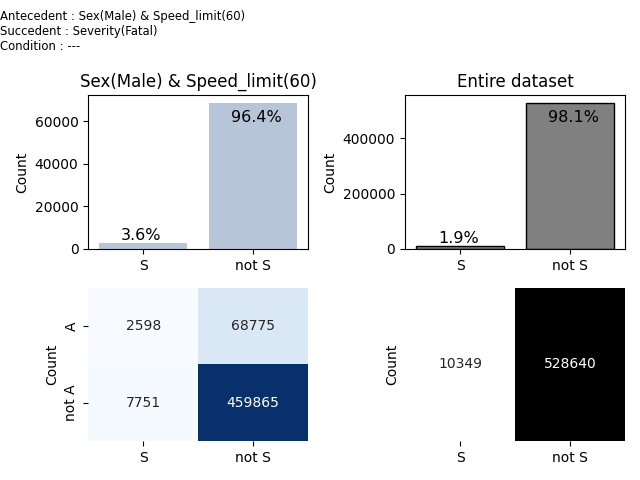
We can see that for Males riding at speed limit 60, the fatality of accidents is 3.6%, and that is +89.6% more than the average on the entire dataset.
In this example, we used only single values of attributes. But CleverMiner (as it is based on the GUHA method) allows to use multiple values for each attribute. We will show it in the following example. First, let us explain input variables and their handling. We want to consider
variables
Driver_Age_BandandSpeed_limitas ordinal where any adjacent categories can be joined. Therefore we use a sequence (abbreviated as seq).a variable
Sexas nominal (technically where any category can be joined, but we defined only 1 category to be used - minlen and maxlen is 1). Therefore we use a subset.a variable
Severityas ordinal where any adjacent categories can be joined and the leftmost one (Fatal) need to be included. Therefore we use a left cut (abbreviated as lcut).
For more details, see Specifying how CleverMiner should combine attributes and their values. Note than minlen and maxlen determines how many categories could be joined (anything in a range between minlen and maxlen).
1import pandas as pd
2import sys
3
4from sklearn.impute import SimpleImputer
5from cleverminer import cleverminer
6
7#read the data
8df = pd.read_csv ('https://www.cleverminer.org/data/accidents.zip', encoding='cp1250', sep='\t')
9df=df[['Driver_Age_Band','Sex','Speed_limit','Severity']]
10
11#handle missing values
12imputer = SimpleImputer(strategy="most_frequent")
13df = pd.DataFrame(imputer.fit_transform(df),columns = df.columns)
14
15clm = cleverminer(df=df,proc='4ftMiner',
16 quantifiers= {'Base':2000, 'aad':0.5},
17 ante ={
18 'attributes':[
19 {'name': 'Driver_Age_Band', 'type': 'seq', 'minlen': 1, 'maxlen': 3},
20 {'name': 'Speed_limit', 'type': 'seq', 'minlen': 1, 'maxlen': 2},
21 {'name': 'Sex', 'type': 'subset', 'minlen': 1, 'maxlen': 1},
22 ], 'minlen':1, 'maxlen':3, 'type':'con'},
23 succ ={
24 'attributes':[
25 {'name': 'Severity', 'type': 'lcut', 'minlen': 1, 'maxlen': 2}
26 ], 'minlen':1, 'maxlen':1 , 'type':'con'}
27 )
28
29clm.print_summary()
30clm.print_rulelist()
31clm.print_rule(13)
32clm.draw_rule(13)
This example gives us following results
CleverMiner task processing summary:
Task type : 4ftMiner
Number of verifications : 488
Number of rules : 13
Total time needed : 00h 00m 00s
Time of data preparation : 00h 00m 00s
Time of rule mining : 00h 00m 00s
List of rules:
RULEID BASE CONF AAD Rule
1 2358 0.031 +0.616 Driver_Age_Band(21 - 25 26 - 35 36 - 45) & Speed_limit(60 70) => Severity(Fatal) | ---
2 2005 0.038 +0.973 Driver_Age_Band(21 - 25 26 - 35 36 - 45) & Speed_limit(60 70) & Sex(Male) => Severity(Fatal) | ---
3 2231 0.033 +0.733 Driver_Age_Band(26 - 35 36 - 45 46 - 55) & Speed_limit(60 70) => Severity(Fatal) | ---
4 2934 0.333 +0.545 Driver_Age_Band(46 - 55) & Speed_limit(50 60) & Sex(Male) => Severity(Fatal Serious) | ---
5 2517 0.328 +0.522 Driver_Age_Band(46 - 55) & Speed_limit(60) & Sex(Male) => Severity(Fatal Serious) | ---
6 4572 0.328 +0.522 Driver_Age_Band(46 - 55 56 - 65) & Speed_limit(50 60) & Sex(Male) => Severity(Fatal Serious) | ---
7 3951 0.324 +0.502 Driver_Age_Band(46 - 55 56 - 65) & Speed_limit(60) & Sex(Male) => Severity(Fatal Serious) | ---
8 3543 0.031 +0.618 Speed_limit(50 60) => Severity(Fatal) | ---
9 3028 0.037 +0.942 Speed_limit(50 60) & Sex(Male) => Severity(Fatal) | ---
10 3064 0.030 +0.583 Speed_limit(60) => Severity(Fatal) | ---
11 2598 0.036 +0.896 Speed_limit(60) & Sex(Male) => Severity(Fatal) | ---
12 4281 0.032 +0.656 Speed_limit(60 70) => Severity(Fatal) | ---
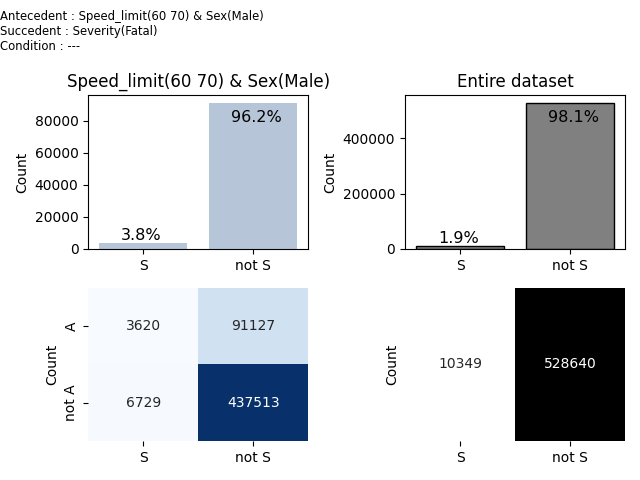
13 3620 0.038 +0.990 Speed_limit(60 70) & Sex(Male) => Severity(Fatal) | ---
Rule id : 13
Base : 3620 Relative base : 0.007 CONF : 0.038 AAD : +0.990 BAD : -0.990
Cedents:
antecedent : Speed_limit(60 70) & Sex(Male)
succcedent : Severity(Fatal)
condition : ---
Fourfold table
| S | ¬S |
----|-----|-----|
A | 3620|91127|
----|-----|-----|
¬A | 6729|437513|
----|-----|-----|
We may see that result was obtained instantly, from 488 verifications we got 13 results. We have listed all rules so we can see that all rules have in succedent Severity(Fatal). In entire dataset, there is 1.9% of Fatal Accidents (see reference chart on the right), For Speed limit 60-70 and Males, there is 3.8% of Fatal accidents (see chart on the left).
Loading and preparing categorical data
CleverMiner is an advanced implementation of association rules. It mines enchanced association rules and works with categorical data. To get most from it (toprepare data into categorical form and see how to work with ordered categories), please read following sections. To ignore it for a fast start, you may load a categorial data into pandas dataframe and start with subset of size 1.
Loading data
As a first step, you need to load the data. Data is loaded into pandas dataframe.
Data matrix is a pandas dataframe. It consists of data lines and attributes. In our examples, we will use dataset Accidents .
Data matrix Accidents is a dataset based on UK Car Accidents Kaggle dataset and looks like:
Row number |
Driver_Age_Band |
Sex |
… |
Severity |
|---|---|---|---|---|
1 |
16-20 |
Male |
… |
Slight |
2 |
46-55 |
Male |
… |
Serious |
3 |
36-45 |
Female |
… |
Slight |
4 |
26-35 |
Male |
… |
Fatal |
… |
… |
… |
… |
… |
We say that Driver_Age_Band(16-20) is valid when Driver_Age_Band='16-20'. Also we say that Driver_Age_Band(16-20) & Sex(Male) is valid when Driver_Age_Band='16-20' and Sex='Male'.
Ensuring data are categorical
You need to ensure that data is prepared in a categorical form. In our example, we already have a categorized variants of numerical attributes, so we only chose the categorical ones.
If it is not the case, there are several possibilities how to do so.
Let show it on an example of attribute Driver_Age
Equidistant categorization
This automatic categorization converts a numeric variable to categories that all categories will have a same width. You can specify the number of categories. The command to do so is df['Age_bins_equidistant'] = pd.cut(df["Driver_Age"], bins=5, duplicates='drop')
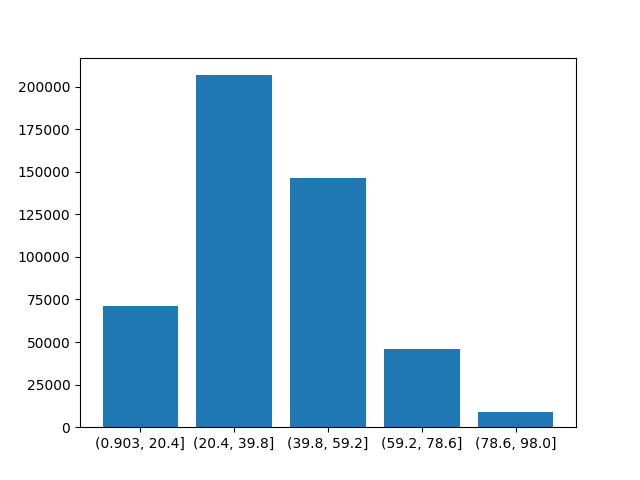
You can see that all bins have approximatelly same size (due to rounding, minor discrepancies may be found), e.g. first bin is 0.9-20.4, that is 19.5 years, second one is 20.4-39.8, that is 19.4 years, …, and the last one is 78.6-98.0, that is 19.4 years
Equifrequent categorization
The next automatic categorization is to split values to bins that each bin has approximatelly the same number of records. Note that this is the most common categorization and obviously, bins are typically not the same width.
The command to do this is df['Age_bins_equifrequent'] = pd.qcut(df["Driver_Age"], q=5, duplicates='drop').
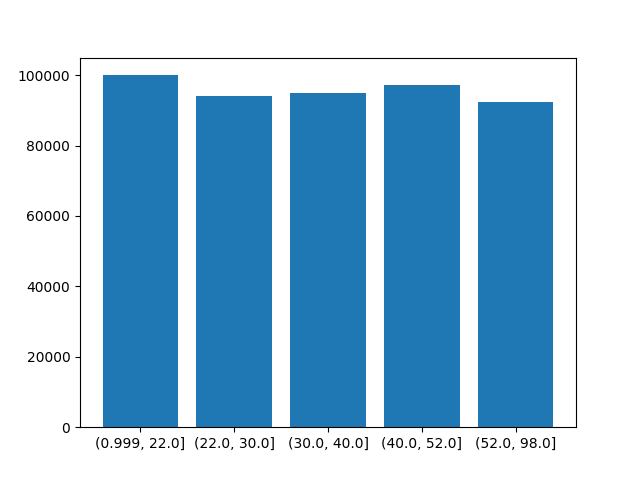
You can see that each bin has approximatelly the same number of records (something less than 100.000), but the and widths are different. The first one is 0.999-22.0, that is 21 years, the second one is 22-30, that is 8 years, the next one is 30-40, that is 10 years, the next one is 40-52, that is 12 years and the last one is 52-98, that is 46 years.
Custom categorization
The last possibility is to create own boundaries, typically for a better interpretation. We have used bins 10 years width except the last that is Over 75.
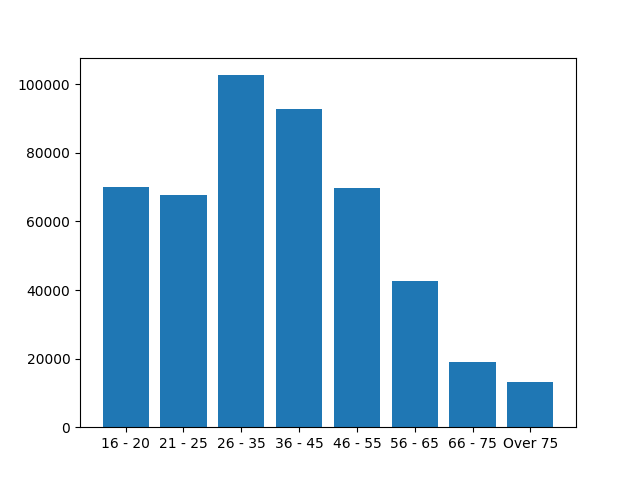
Ordering categories
CleverMiner supports joining of ordered categories. In order to work properly, data should be ordered. That is tricky for string labels like 1-5,*6-9*,*11-20*,…,*101 and more* where string ordering does not work.
CleverMiner tries to order categories automatically. You can verify the ordering by using clm.print_data_definition(). So we will select several categorical variables and see the results.
import pandas as pd
import matplotlib.pyplot as plt
from cleverminer import cleverminer
df = pd.read_csv ('accidents.zip', encoding='cp1250', sep='\t')
df=df[['Driver_Age_Band','Driver_IMD','Sex','Area','Journey','Road_Type','Speed_limit','Light','Vehicle_Location','Vehicle_Type','Vehicle_Age','Hit_Objects_in','Hit_Objects_off','Casualties','Severity']]
clm = cleverminer(df=df)
clm.print_data_definition()
Dataset has 15 variables.
Variable Driver_Age_Band has 8 categories: 16 - 20 21 - 25 26 - 35 36 - 45 46 - 55 56 - 65 66 - 75 Over 75
Variable Driver_IMD has 10 categories: 1 2 3 4 5 6 7 8 9 10
Variable Sex has 2 categories: Female Male
Variable Area has 2 categories: 1,Urban 2,Rural
Variable Journey has 5 categories: 2,Commuting to/from work 3,Taking pupil to/from school 4,Pupil riding to/from school 5 Other/Not known Part of work
Variable Road_Type has 5 categories: 1,Roundabout 2,One way street 3,Dual carriageway 6,Single carriageway 7,Slip road
Variable Speed_limit has 8 categories: 10 15 20 30 40 50 60 70
Variable Light has 5 categories: 1,Daylight 4,Darkness - lights lit 5,Darkness - lights unlit 6,Darkness - no lighting 7,Darkness - lighting unknown
Variable Vehicle_Location has 10 categories: 0,On main c'way - not in restricted lane 1,Tram/Light rail track 2,Bus lane 3,Busway (including guided busway) 4,Cycle lane (on main carriageway) 5,Cycleway or shared use footway (not part of main carriageway) 6,On lay-by or hard shoulder 7,Entering lay-by or hard shoulder 8,Leaving lay-by or hard shoulder 9,Footway (pavement)
Variable Vehicle_Type has 20 categories: 10,Minibus (8 - 16 passenger seats) 16,Ridden horse 17,Agricultural vehicle 18,Tram 20,Goods over 3.5t. and under 7.5t 21,Goods 7.5 tonnes + 22,Mobility scooter 23,Electric motorcycle 4,Motorcycle over 125cc and up to 500cc 90,Other vehicle 97,Motorcycle - unknown cc 98,Goods vehicle - unknown weight Bus_coach_17+ Car Motorcycle 125cc and under Motorcycle 50cc and under Motorcycle over 500cc Pedal cycle Taxi/Private hire car Van / Goods 3.5 tonnes mgw or under
Variable Vehicle_Age has 17 categories: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16-20 >20
Variable Hit_Objects_in has 12 categories: 0 1 2 4 5 6 7 8 9 10 11 12
Variable Hit_Objects_off has 12 categories: 0 1 2 3 4 5 6 7 8 9 10 11
Variable Casualties has 7 categories: 1 2 3 4 5 6 7 - 68
Variable Severity has 3 categories: Fatal Serious Slight
So we can see that Driver_Age_Band is ok as well as Driver_IMD, numbered labels in Area,*Journey*, Light, Vehicle_Type and Vehicle_Location as well. Also Hit_Objects_in and Hit_Objects_off are ok, as well as Vehicle_Age.
If some attribute is not sorted properly in automatic sorting (e.g. as for Adults data set and Education attribute), own ordering can be defined an ordered list of categories and by setting type of attribute as ordered categorical.
edu_cat = ["Preschool", "1st-4th", "5th-6th", "7th-8th", "9th", "10th", "11th", "12th", "HS-grad", "Some-college", "Assoc-voc", "Assoc-acdm", "Bachelors", "Masters", "Prof-school", "Doctorate"]
edu_cat_type = CategoricalDtype(categories=edu_cat, ordered=True)
df['Education'] = df['Education'].astype('category').cat.reorder_categories(edu_cat,ordered=True)
Profiling categorical data
Categorical data can be easily profiled by any of leading self-service BI tools (including Excel pivot table for data up to 1M rows, or PowerBI/Tableau tools for higher volumes or advanced profiling).
For profiling categorical data, you can use ydata-profiling package (which is excellent but it is designed mainly for continuous variables – for categorical variables there is only several first most frequent shown and does not support ordering of categories; advanced functions are not suitable for them) so we have developed a separate package pandas-cat dedicated to categorical variable profiling (see https://pypi.org/project/pandas-cat/)
You can also see the sample profile report for Accidents data set (values and their occurrence) which is available here.
Note
Input dataset is panda dataframe where all attributes should be categorial. Note that all attributes are prepared to internal binary bitchain form so if you have large dataset with many unused attributes please consider to reduce this dataset to improve computing time.
Note
All attributes should be categorial. The package tries to order attributes automatically either for output listing, or for ordinal attribute handling (like using sequences and cuts, see below). Cleverminer tries to detect numeric values automatically, if they are not prepared in ordered form.
Note
To prevent huge memory requirements and computation times (typically by omitting categorization of attribute), the number of allowed categories (unique values) per variable is limited to a default (big enough) value. If needed, this value can be increased (see Advanced options (expert use only))
Specifying how CleverMiner should combine attributes and their values
Let have a rule Driver_Age_Band(46 - 55) & Speed_limit(60) & Sex(Male) => Severity(Fatal Serious). Then, we call left-hand side (Driver_Age_Band(46 - 55) & Speed_limit(60) & Sex(Male)) and right-hand side (Severity(Fatal Serious))of the rule as cedents.
Combination of attributes and values, in our case Driver_Age_Band(46 - 55), Speed_limit(60), Sex(Male) and Severity(Fatal Serious) we call literals. Cedent is combination (conjunction or disjunction) of literals.
We have showed a specific rule. For CleverMiner, you need to setup a pattern of rules to be verified.
Literals and cedents
When we want to search for all possible values (combination of values) of attributes Driver_Age_Band and Sex, we will use Driver_Age_Band(*) & Sex(*).
Cedent is combination of literals (conjunction or disjunction). You can define minimal and maximal cedent length. When you use cedent consisting of attributes Driver_Age_Band and Sex and maximum length is 1, all values of Driver_Age_Band are generated and all possible of Sex are generated. When length is exactly 2, all possible combinations of Driver_Age_Band and Sex attribute values are generated as a cedent. When length of cedent can be 1-2, both single attribute-value and pairs of attribute-values are generated.
Cedent consist of literals. Each literal is attribute and its possible values.
ante ={
'attributes':[
{'name': 'Driver_Age_Band', 'type': 'seq', 'minlen': 1, 'maxlen': 3},
{'name': 'Speed_limit', 'type': 'seq', 'minlen': 1, 'maxlen': 2},
{'name': 'Sex', 'type': 'subset', 'minlen': 1, 'maxlen': 1},
], 'minlen':1, 'maxlen':2, 'type':'con'},
In previous example, we may see cedent of length 1 to 3 (that means that 1 or 2 attributes may be present in the rule) where first two attributes are type seq(sequence) and the third one is type of subset. All literal types contains minimal and maximal length (number of values).
Cedent has list of literals (definition and possible values are outlined in Literals section) and parameters how to combine them. In our example, we have
ante ={'attributes':[...], 'minlen':2, 'maxlen':2, 'type':'con'},. Meaning of the attribute is the following:
type - type of cedent – how literals (attributes and values) are combined - available values are
conanddisfor conjunction/disjunctionminlen – number, minimal length of cedent (minimal number of literals in the cedent in the rule)
maxlen – number, maximal length of cedent (maximal number of literals in the cedent in the rule)
Note
Number of attributes and mainly length of cedents is key to the complexity of the task (time needed). Start with smaller number first and expand when needed.
Literals
Each definition of a set of relevant cedents contain the list of attributes. For example {'name': 'Driver_Age_Band', 'type': 'seq', 'minlen': 1, 'maxlen': 3} denotes that we will
use Driver_Age_Limit attribute as a sequence (see Literal types.)
For each literal, following parameters to be specified:
name – name of attribute A (must correspond to existing attribute name in pandas dataframe)
type – available values are subset for subsets, lcut for left cut, rcut for right cut, seq sequence, one for one category (type defines a type of a set a in literal A(a), see following section)
minlen – number, minimal number of categories (i.e. values of A) in the literal A(a)
maxlen – number, maximal number of categories in the literal A(a)
Note
Number of values and mainly length of literal is the second key to the complexity of the task (time needed). Start with smaller number first and expand when needed.
Literal types
CleverMiner support single value of attiribute as well as multiple values. For example, Driver_Age_Band(16-20 21-25) denotes that Driver_Age_Band can be either 16-20 or 21-25. You can specify how many values is generated to possible rules
and how values are generated. The simplest way is to generate subsets. If you generate subsets of length 1-2, all single values of the attribute is used as well as all pairs of values of the attributes is used (e.g. 16-20 36-45). Note that subsets
are suitable for nominal (unordered) attributes (because interpretation of joining non-neighbouring categories is hard). Therefore CleverMiner supports several literal types.
Available literal types are
subset - all subsets of length minlen to maxlen are verified
seq - sequences of length minlen to maxlen are verified
lcut - left cuts of length minlen to maxlen are verified
rcut - right cuts of length minlen to maxlen are verified
one - one category, value key denotes which category will be used
Let have attribute Severity with values Fatal, Serious and Slight (in this order).
Subsets
Let us repeat that subsets are all possible combinations of values.
There are 3 possible subsets of length 1 (1 to 1):
Combination# |
Fatal |
Serious |
Slight |
Meaning (one of these values) |
|---|---|---|---|---|
1 |
X |
{Fatal} |
||
2 |
X |
{Serious} |
||
3 |
X |
{Slight} |
When we take all possible subsets of length 2, we will get
Combination# |
Fatal |
Serious |
Slight |
Meaning (one of these values) |
|---|---|---|---|---|
1 |
X |
X |
{Fatal, Serious} |
|
2 |
X |
X |
{Serious, Slight} |
|
3 |
X |
X |
{Fatal, Slight} |
And all possible subsets of length 1-2 are
Combination# |
Fatal |
Serious |
Slight |
Meaning (one of these values) |
|---|---|---|---|---|
1 |
X |
{Fatal} |
||
2 |
X |
{Serious} |
||
3 |
X |
{Slight} |
||
4 |
X |
X |
{Fatal, Serious} |
|
5 |
X |
X |
{Serious, Slight} |
|
6 |
X |
X |
{Fatal, Slight} |
Sequences
Let us repeat that sequences are sets of following values (categories) for ordinal attributes. This feature allow joining of neighbouring categories. As we saw in the previous example, subsets of length 2 also suggests a combination of Fatal and Slight categories. Non-neighbouring categories are typically hard to interpret, therefore sequences and cuts has been introduced in GUHA method.
All sequences of length 2 are
Combination# |
Fatal |
Serious |
Slight |
Meaning (one of these values) |
|---|---|---|---|---|
1 |
X |
X |
{Fatal, Serious} |
|
2 |
X |
X |
{Serious, Slight} |
Sequences of length 1-2 are
Combination# |
Fatal |
Serious |
Slight |
Meaning (one of these values) |
|---|---|---|---|---|
1 |
X |
{Fatal} |
||
2 |
X |
{Serious} |
||
3 |
X |
{Slight} |
||
4 |
X |
X |
{Fatal, Serious} |
|
5 |
X |
X |
{Serious, Slight} |
Left and right cuts
Left anr right cuts are suitable for ordinal attributes.
Left cuts are sequences that begins with leftmost value. So left cuts of length 1-2 are
Combination# |
Fatal |
Serious |
Slight |
Meaning (one of these values) |
|---|---|---|---|---|
1 |
X |
{Fatal} |
||
2 |
X |
X |
{Fatal,Serious} |
In a same way, right cuts of length 1-2 are
Combination# |
Fatal |
Serious |
Slight |
Meaning (one of these values) |
|---|---|---|---|---|
1 |
X |
{Slight} |
||
2 |
X |
X |
{Serious, Slight} |
One value
And last, one value can be specified that only one given value is used and such value is specified. E.g. Fatal will give only one possible “combination”.
Combination# |
Fatal |
Serious |
Slight |
Meaning (one of these values) |
|---|---|---|---|---|
1 |
X |
{Fatal} |
Machine Learning procedures available in CleverMiner
This section shows which type of tasks you may solve with CleverMiner. CleverMiner procedures are implementation of GUHA procedures. Each procedure can solve different type of task and mine different pattern of rules. In general, you will specify which attributes to use and how can individual values be combined and CleverMiner will try all possibilities and verify condition (e.g. at least 50% of cases that satisfy A must also satisfy B where A and B is valid for at least 100 cases).
CleverMiner is a set of procedures for mining interesting pattern. Each procedure is different and have different requirements how the possible rules look like and in a way how to filter out interesting rules. Currently, CleverMiner supports 4 procedures 4ft-Miner, CF-Miner, SD4ft Miner and UIC Miner.
Note
Every procedure consists of cedents (e.g left hand side and right hand side of association rules). Full possibilities how to define cedents are shown in following section. For now, let assume that cedent is conjuction/disjunction of literals and literal is condition that attribute has one of specified values.
General cleverminer procedure call
CleverMiner is a Python library (class). It loads Panda dataframe with categorial data, prepares it to internal format for quick patterns mining and applies GUHA procedure.
import pandas as pd
import sys
from cleverminer import cleverminer
#prepare panda dataset here
clm = cleverminer(df=df, proc=<procedure>,
quantifiers = <quantifiers>,
ante = <cedent>,
succ = <cedent>,
cond = <cedent>,
target = <varname>)
cleverminer.print_rulelist(clm)
where df is panda dataframe with all variables categorised (number of distinct values should be small) proc is a GUHA procedure. Currently supported procedures are 4ftMiner, CFMiner and SD4ftMiner quantifier is a list of conditions (based on procedure, see section for individual procedure) target is name of target variable (applicable for CFMiner procedure only) cedent (ante, succ, cond, …) is a definition of a set of relevant cedents cedent (cedent is a conjunction or disjunction of literals). Literal is in a form \(A(a)\) where A is an attribute and a is a subset of its values.
In the following text, we will use this data load and preparation
import pandas as pd
import sys
import sklearn.impute
from matplotlib import pyplot as plt
from sklearn.impute import SimpleImputer
from cleverminer import cleverminer
df = pd.read_csv ('w:\\development\\cleverminer\\_data\\accidents.txt ', encoding='cp1250', sep='\t')
df=df[['Driver_Age_Band','Driver_IMD','Sex','Area','Journey','Road_Type','Speed_limit','Light','Vehicle_Location','Vehicle_Type','Vehicle_Age','Hit_Objects_in','Hit_Objects_off','Casualties','Severity']]
imputer = SimpleImputer(strategy="most_frequent")
df = pd.DataFrame(imputer.fit_transform(df),columns = df.columns)
Full example of procedure call is here
clm = cleverminer(df=df,proc='4ftMiner',
quantifiers= {'Base':2000, 'aad':0.4},
ante ={
'attributes':[
{'name': 'Driver_Age_Band', 'type': 'seq', 'minlen': 1, 'maxlen': 3},
{'name': 'Speed_limit', 'type': 'seq', 'minlen': 1, 'maxlen': 2},
{'name': 'Sex', 'type': 'subset', 'minlen': 1, 'maxlen': 1},
], 'minlen':1, 'maxlen':3, 'type':'con'},
succ ={
'attributes':[
{'name': 'Severity', 'type': 'lcut', 'minlen': 1, 'maxlen': 2}
], 'minlen':1, 'maxlen':1 , 'type':'con'}
)
clm.print_summary()
clm.print_rulelist()
clm.print_rule(8)
Procedures and supported quantifiers follow immediatelly.
4ft-Miner
Motivation
Basic idea is to find rules If A then S with probability at least p and which is valid for at least Base records.
Searched pattern
4ft Miner procedure looks for rules \(A\Rightarrow_{p,Base} S\), where \(A = A_1(a_1) \& A_2(a_2) \& \dots \& A_n(a_n)\) is called antecedent and \(S = S_1(s_1) \& S_2(s_2) \& \dots \& S_m(s_m)\) is called succedent, \(C = C_1(c_1) \& C_2(c_2) \& \dots \& C_k(c_k)\) is called condition in case of conjunction. Note that and all of cedents can be conjuction or disjunction of attributes and its values. This procedure search all possible attributes and its values and verifies it against conditions call quantifiers (typically p = minimal conditional probability \(P(S|A)\) and Base denotes minimal number of records that satisfies both A and S. Dataset is filtered out to records that satisfy condition C.
Cedents to be defined for 4ftMiner are
ante - antecedent (or left hand side of the rule)
succ succedent (or right hand side of the rule)
cond condition
Note
Condition is optional in 4ftMiner. If you want to use 4ftMiner without condition, simply omit this cedent in procedure call.
Example of call
As an example, we will use following code
clm = cleverminer(df=df,proc='4ftMiner',
quantifiers= {'Base':20000, 'aad':0.7},
ante ={
'attributes':[
{'name': 'Driver_Age_Band', 'type': 'seq', 'minlen': 1, 'maxlen': 3},
{'name': 'Driver_IMD', 'type': 'seq', 'minlen': 1, 'maxlen': 3},
{'name': 'Sex', 'type': 'subset', 'minlen': 1, 'maxlen': 1},
{'name': 'Journey', 'type': 'subset', 'minlen': 1, 'maxlen': 1}
], 'minlen':1, 'maxlen':4, 'type':'con'},
succ ={
'attributes':[
{'name': 'Hit_Objects_in', 'type': 'rcut', 'minlen': 1, 'maxlen': 11},
{'name': 'Hit_Objects_off', 'type': 'rcut', 'minlen': 1, 'maxlen': 11},
{'name': 'Casualties', 'type': 'rcut', 'minlen': 1, 'maxlen': 6},
{'name': 'Severity', 'type': 'lcut', 'minlen': 1, 'maxlen': 2}
], 'minlen':1, 'maxlen':1 , 'type':'con'}
)
clm.print_rulelist()
clm.print_summary()
clm.print_rule(1)
Running the task will give us the output
List of rules:
RULEID BASE CONF AAD Rule
1 20995 0.300 +0.736 Driver_Age_Band(16 - 20) => Hit_Objects_off(11 10 9 8 7 6) | ---
2 21193 0.303 +0.731 Driver_Age_Band(16 - 20) => Hit_Objects_off(11 10 9 8 7 6 5) | ---
3 28716 0.410 +0.763 Driver_Age_Band(16 - 20) => Hit_Objects_off(11 10 9 8 7 6 5 4) | ---
4 30371 0.434 +0.775 Driver_Age_Band(16 - 20) => Hit_Objects_off(11 10 9 8 7 6 5 4 3) | ---
5 33931 0.485 +0.776 Driver_Age_Band(16 - 20) => Hit_Objects_off(11 10 9 8 7 6 5 4 3 2) | ---
6 36507 0.521 +0.755 Driver_Age_Band(16 - 20) => Hit_Objects_off(11 10 9 8 7 6 5 4 3 2 1) | ---
7 20419 0.401 +0.724 Driver_Age_Band(16 - 20) & Sex(Male) => Hit_Objects_off(11 10 9 8 7 6 5 4) | ---
8 21623 0.425 +0.738 Driver_Age_Band(16 - 20) & Sex(Male) => Hit_Objects_off(11 10 9 8 7 6 5 4 3) | ---
9 24414 0.479 +0.758 Driver_Age_Band(16 - 20) & Sex(Male) => Hit_Objects_off(11 10 9 8 7 6 5 4 3 2) | ---
10 26293 0.516 +0.739 Driver_Age_Band(16 - 20) & Sex(Male) => Hit_Objects_off(11 10 9 8 7 6 5 4 3 2 1) | ---
11 21438 0.492 +0.804 Driver_Age_Band(16 - 20) & Sex(Male) & Journey(5 Other/Not known) => Hit_Objects_off(11 10 9 8 7 6 5 4 3 2) | ---
12 23085 0.530 +0.784 Driver_Age_Band(16 - 20) & Sex(Male) & Journey(5 Other/Not known) => Hit_Objects_off(11 10 9 8 7 6 5 4 3 2 1) | ---
13 24614 0.418 +0.797 Driver_Age_Band(16 - 20) & Journey(5 Other/Not known) => Hit_Objects_off(11 10 9 8 7 6 5 4) | ---
14 26010 0.442 +0.808 Driver_Age_Band(16 - 20) & Journey(5 Other/Not known) => Hit_Objects_off(11 10 9 8 7 6 5 4 3) | ---
15 29165 0.495 +0.816 Driver_Age_Band(16 - 20) & Journey(5 Other/Not known) => Hit_Objects_off(11 10 9 8 7 6 5 4 3 2) | ---
16 31402 0.533 +0.795 Driver_Age_Band(16 - 20) & Journey(5 Other/Not known) => Hit_Objects_off(11 10 9 8 7 6 5 4 3 2 1) | ---
17 24288 0.176 +0.708 Driver_Age_Band(16 - 20 21 - 25) => Hit_Objects_off(11 10) | ---
18 21282 0.216 +0.825 Driver_Age_Band(16 - 20 21 - 25) & Sex(Male) => Casualties(7 - 68 6 5 4 3 2) | ---
19 21117 0.265 +0.701 Driver_Age_Band(16 - 20 21 - 25) & Sex(Male) & Journey(5 Other/Not known) => Hit_Objects_off(11 10 9 8 7) | ---
20 37225 0.467 +0.712 Driver_Age_Band(16 - 20 21 - 25) & Sex(Male) & Journey(5 Other/Not known) => Hit_Objects_off(11 10 9 8 7 6 5 4 3 2) | ---
21 40392 0.507 +0.706 Driver_Age_Band(16 - 20 21 - 25) & Sex(Male) & Journey(5 Other/Not known) => Hit_Objects_off(11 10 9 8 7 6 5 4 3 2 1) | ---
22 20287 0.185 +0.796 Driver_Age_Band(16 - 20 21 - 25) & Journey(5 Other/Not known) => Hit_Objects_off(11 10) | ---
23 25706 0.235 +0.754 Driver_Age_Band(16 - 20 21 - 25) & Journey(5 Other/Not known) => Hit_Objects_off(11 10 9) | ---
24 25786 0.236 +0.754 Driver_Age_Band(16 - 20 21 - 25) & Journey(5 Other/Not known) => Hit_Objects_off(11 10 9 8) | ---
25 29153 0.266 +0.711 Driver_Age_Band(16 - 20 21 - 25) & Journey(5 Other/Not known) => Hit_Objects_off(11 10 9 8 7) | ---
26 50995 0.466 +0.709 Driver_Age_Band(16 - 20 21 - 25) & Journey(5 Other/Not known) => Hit_Objects_off(11 10 9 8 7 6 5 4 3 2) | ---
27 25119 0.230 +0.943 Driver_Age_Band(16 - 20 21 - 25) & Journey(5 Other/Not known) => Casualties(7 - 68 6 5 4 3 2) | ---
CleverMiner task processing summary:
Task type : 4ftMiner
Number of verifications : 1296
Number of rules : 27
Total time needed : 00h 00m 05s
Time of data preparation : 00h 00m 01s
Time of rule mining : 00h 00m 03s
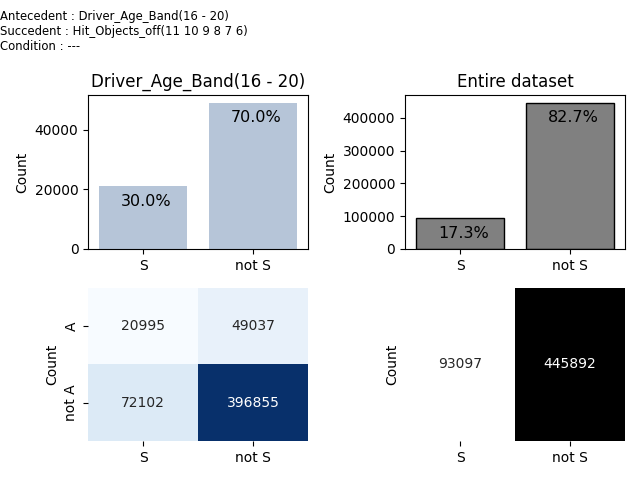
Rule id : 1
Base : 20995 Relative base : 0.039 CONF : 0.300 AAD : +0.736 BAD : -0.736
Cedents:
antecedent : Driver_Age_Band(16 - 20)
succcedent : Hit_Objects_off(11 10 9 8 7 6)
condition : ---
Fourfold table
| S | ¬S |
----|-----|-----|
A |20995|49037|
----|-----|-----|
¬A |72102|396855|
----|-----|-----|
We can see that Hit_objects_Off values 6-11 have occurence 17.3% on entire dataset while it has occurence 30.0% in an Age group 16-20.
Quantifiers available
Quantifiers are inputs from analyst to filter out only interesting rules. These inputs can be
For quantifiers, available parameters are
base - Base, minimal absolute number of items satisfying both antecedent and succedent, given by condition respectively
relbase - Relative base, Base divided by total number of items, given by condition respectively
conf - confidence - conditional probability of P(S|A) or what is the percentage of items that satisfies S from items that satisfies A
aad - above average difference - P(S|A)/P(S)-1 or how many times is probability of S increased when using only records that satisfy A compared to all records (how much A improves probability of S) minus one, i.e. how much is the probability increased.
bad - below average difference - negative value of aad how much A decreases probability of S
SD4ft Miner
Motivation
Basic idea is to find rules Find me circumstances, under which probability of rule (e.g. high severity of accidents) differs a lot.. For example, you may check whether under fixed circumstances, there is a huge difference in probability of Fatal accident between yound and old people.
Searched pattern
SD4ft Miner procedure looks for change in attributes in 4ft Miner like rules that changes conf (confidence, or implied probability) at least by defined value.
Cedents to be defined for SD4ftMiner are
ante - antecedent (or left hand side of the rule)
succ - succedent (or right hand side of the rule)
frst - first set (sub-matrix used in first rule)
scnd - second set (sub-matrix used in second rule)
cond - condition
Note
Condition is optional in SD4ft-Miner. If you want to use SD4ft-Miner without condition, simply omit this cedent in procedure call.
Example of call
As an example, we will use following code
clm = cleverminer(df=df,proc='SD4ftMiner',
quantifiers= {'Base1':4000,'Base2':4000, 'Ratiopim':1.4},
ante ={
'attributes':[
{'name': 'Vehicle_Type', 'type': 'subset', 'minlen': 1, 'maxlen': 1},
{'name': 'Speed_limit', 'type': 'seq', 'minlen': 1, 'maxlen': 2},
], 'minlen':1, 'maxlen':4, 'type':'con'},
succ ={
'attributes':[
{'name': 'Severity', 'type': 'lcut', 'minlen': 1, 'maxlen': 2}
], 'minlen':1, 'maxlen':1 , 'type':'con'},
frst ={
'attributes':[
{'name': 'Driver_Age_Band', 'type': 'seq', 'minlen': 1, 'maxlen': 3}
], 'minlen':1, 'maxlen':1, 'type':'con'},
scnd ={
'attributes':[
{'name': 'Driver_Age_Band', 'type': 'seq', 'minlen': 1, 'maxlen': 3}
], 'minlen':1, 'maxlen':1, 'type':'con'}
# ,opts = {'no_optimizations':True,'max_categories':20}
)
clm.print_summary()
clm.print_rulelist()
clm.print_rule(1)
The output is in the following block.
CleverMiner task processing summary:
Task type : SD4ftMiner
Number of verifications : 14994
Number of rules : 19
Total time needed : 00h 00m 27s
Time of data preparation : 00h 00m 01s
Time of rule mining : 00h 00m 25s
List of rules:
RULEID BASE1 BASE2 RatioConf DeltaConf Rule
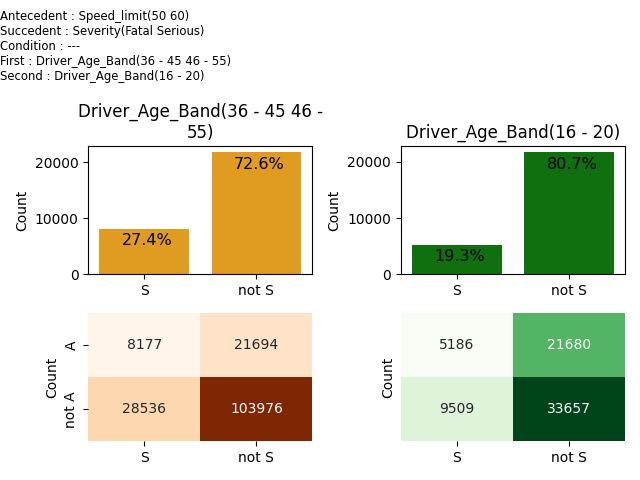
1 8177 5186 1.418 +0.081 Speed_limit(50 60) => Severity(Fatal Serious) | --- : Driver_Age_Band(36 - 45 46 - 55) x Driver_Age_Band(16 - 20)
2 7134 4675 1.411 +0.079 Speed_limit(60) => Severity(Fatal Serious) | --- : Driver_Age_Band(36 - 45 46 - 55) x Driver_Age_Band(16 - 20)
3 10160 5186 1.430 +0.083 Speed_limit(50 60) => Severity(Fatal Serious) | --- : Driver_Age_Band(36 - 45 46 - 55 56 - 65) x Driver_Age_Band(16 - 20)
4 8868 4675 1.422 +0.081 Speed_limit(60) => Severity(Fatal Serious) | --- : Driver_Age_Band(36 - 45 46 - 55 56 - 65) x Driver_Age_Band(16 - 20)
5 12112 5445 1.403 +0.077 Speed_limit(60 70) => Severity(Fatal Serious) | --- : Driver_Age_Band(36 - 45 46 - 55 56 - 65) x Driver_Age_Band(16 - 20)
6 4224 5445 1.469 +0.089 Speed_limit(60 70) => Severity(Fatal Serious) | --- : Driver_Age_Band(46 - 55) x Driver_Age_Band(16 - 20)
7 4224 10324 1.426 +0.084 Speed_limit(60 70) => Severity(Fatal Serious) | --- : Driver_Age_Band(46 - 55) x Driver_Age_Band(16 - 20 21 - 25)
8 5521 5186 1.492 +0.095 Speed_limit(50 60) => Severity(Fatal Serious) | --- : Driver_Age_Band(46 - 55 56 - 65) x Driver_Age_Band(16 - 20)
9 4783 4675 1.474 +0.091 Speed_limit(60) => Severity(Fatal Serious) | --- : Driver_Age_Band(46 - 55 56 - 65) x Driver_Age_Band(16 - 20)
10 6583 5445 1.465 +0.088 Speed_limit(60 70) => Severity(Fatal Serious) | --- : Driver_Age_Band(46 - 55 56 - 65) x Driver_Age_Band(16 - 20)
11 5521 9557 1.418 +0.085 Speed_limit(50 60) => Severity(Fatal Serious) | --- : Driver_Age_Band(46 - 55 56 - 65) x Driver_Age_Band(16 - 20 21 - 25)
12 4783 8482 1.404 +0.082 Speed_limit(60) => Severity(Fatal Serious) | --- : Driver_Age_Band(46 - 55 56 - 65) x Driver_Age_Band(16 - 20 21 - 25)
13 6583 10324 1.422 +0.083 Speed_limit(60 70) => Severity(Fatal Serious) | --- : Driver_Age_Band(46 - 55 56 - 65) x Driver_Age_Band(16 - 20 21 - 25)
14 6418 5186 1.480 +0.093 Speed_limit(50 60) => Severity(Fatal Serious) | --- : Driver_Age_Band(46 - 55 56 - 65 66 - 75) x Driver_Age_Band(16 - 20)
15 5577 4675 1.464 +0.089 Speed_limit(60) => Severity(Fatal Serious) | --- : Driver_Age_Band(46 - 55 56 - 65 66 - 75) x Driver_Age_Band(16 - 20)
16 7633 5445 1.457 +0.087 Speed_limit(60 70) => Severity(Fatal Serious) | --- : Driver_Age_Band(46 - 55 56 - 65 66 - 75) x Driver_Age_Band(16 - 20)
17 6418 9557 1.407 +0.083 Speed_limit(50 60) => Severity(Fatal Serious) | --- : Driver_Age_Band(46 - 55 56 - 65 66 - 75) x Driver_Age_Band(16 - 20 21 - 25)
18 7633 10324 1.414 +0.081 Speed_limit(60 70) => Severity(Fatal Serious) | --- : Driver_Age_Band(46 - 55 56 - 65 66 - 75) x Driver_Age_Band(16 - 20 21 - 25)
19 4100 5445 1.439 +0.084 Speed_limit(60 70) => Severity(Fatal Serious) | --- : Driver_Age_Band(56 - 65 66 - 75 Over 75) x Driver_Age_Band(16 - 20)
Rule id : 1
Base1 : 8177 Base2 : 5186 Relative base 1 : 0.015 Relative base 2 : 0.010 CONF1 : 0.274 CONF2 : +0.193 Delta Conf : +0.081 Ratio Conf : +1.418
Cedents:
antecedent : Speed_limit(50 60)
succcedent : Severity(Fatal Serious)
condition : ---
first set : Driver_Age_Band(36 - 45 46 - 55)
second set : Driver_Age_Band(16 - 20)
Fourfold tables:
FRST| S | ¬S | SCND| S | ¬S |
----|-----|-----| ----|-----|-----|
A | 8177|21694| A | 5186|21680|
----|-----|-----| ----|-----|-----|
¬A |28536|103976| ¬A | 9509|33657|
----|-----|-----| ----|-----|-----|
The first rule is visualised in the following chart. We can see that Age Groups 36-55 (joined 36-45 and 46-55) and 16-20 behaves differently when Speed_Limit is 50-60. The first one has risk of Serious/Fatal accident 27.4% while the second one has risk of Serious/Fatal accident 19.3%.
Quantifiers available
For quantifiers, available parameters are
FrstBase - Base, minimal absolute number of items satisfying both antecedent and succedent, given by condition respectively for the first rule
ScndBase - Base, minimal absolute number of items satisfying both antecedent and succedent, given by condition respectively for the second rule
FrstRelBase - Relative base, Base divided by total number of items for the first rule
ScndRelBase - Relative base, Base divided by total number of items for the second rule
Frstconf - confidence - conditional probability of P(S|A) or what is the percentage of items that satisfies S from items that satisfies A for the first rule
Scndconf - confidence - conditional probability of P(S|A) or what is the percentage of items that satisfies S from items that satisfies A for the second rule
Deltaconf - absolute difference of confidences in first and second rule
Ratioconf - relative difference of confidences in first and second rule
Ratioconf_leq - relative difference of confidences in first and second rule - upper bound
CF-Miner
Motivation
Basic idea is to find rules Find me circumstances under which accident severity is raising.
Therefore CF-Miner looks for interesting histogram.
Searched pattern
CFMiner procedure finds histogram of target variable given by specified condition (cedent). For example, if share price is growing, you may look for share types by several atributes for which share price is declining.
This procedure has single cedent cond that denotes condition.
Example of call
Example of CFMiner procedure call is here. As histogram of Severity is raising (lower severity = bigger occurence), will look for histograms (occurences) where there is at least 1 step down in Severity.
clm = cleverminer(df=df,target='Severity',proc='CFMiner',
quantifiers= {'S_Down':1, 'Base':100},
cond ={
'attributes':[
{'name': 'Driver_Age_Band', 'type': 'seq', 'minlen': 1, 'maxlen': 3},
{'name': 'Driver_IMD', 'type': 'seq', 'minlen': 1, 'maxlen': 3},
{'name': 'Sex', 'type': 'subset', 'minlen': 1, 'maxlen': 1},
{'name': 'Journey', 'type': 'subset', 'minlen': 1, 'maxlen': 1},
{'name': 'Speed_limit', 'type': 'seq', 'minlen': 1, 'maxlen': 3},
{'name': 'Light', 'type': 'subset', 'minlen': 1, 'maxlen': 1},
{'name': 'Vehicle_Type', 'type': 'subset', 'minlen': 1, 'maxlen': 1}
], 'minlen':1, 'maxlen':2, 'type':'con'}
)
clm.print_rulelist()
clm.print_summary()
clm.print_rule(1)
The output is the following:
List of rules:
RULEID BASE S_UP S_DOWN Condition
1 10571 1 1 Speed_limit(40 50 60) & Vehicle_Type(Motorcycle over 500cc)
2 8803 1 1 Speed_limit(50 60) & Vehicle_Type(Motorcycle over 500cc)
3 1143 1 1 Speed_limit(50 60) & Vehicle_Type(Pedal cycle)
4 10690 1 1 Speed_limit(50 60 70) & Vehicle_Type(Motorcycle over 500cc)
5 1198 1 1 Speed_limit(50 60 70) & Vehicle_Type(Pedal cycle)
6 7694 1 1 Speed_limit(60) & Vehicle_Type(Motorcycle over 500cc)
7 996 1 1 Speed_limit(60) & Vehicle_Type(Pedal cycle)
8 9581 1 1 Speed_limit(60 70) & Vehicle_Type(Motorcycle over 500cc)
9 1051 1 1 Speed_limit(60 70) & Vehicle_Type(Pedal cycle)
CleverMiner task processing summary:
Task type : CFMiner
Number of verifications : 3317
Number of rules : 9
Total time needed : 00h 00m 02s
Time of data preparation : 00h 00m 01s
Time of rule mining : 00h 00m 00s
Rule id : 1
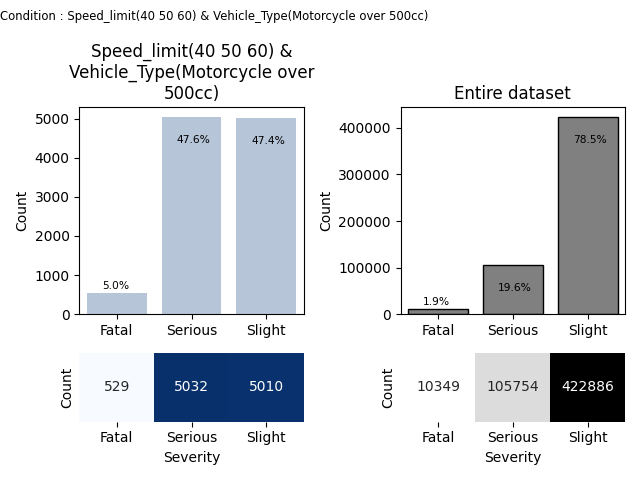
Base : 10571 Relative base : 0.020 Steps UP (consecutive) : 1 Steps DOWN (consecutive) : 1 Steps UP (any) : 1 Steps DOWN (any) : 1 Histogram maximum : 5032 Histogram minimum : 529 Histogram relative maximum : 0.476 Histogram relative minimum : 0.050
Condition : Speed_limit(40 50 60) & Vehicle_Type(Motorcycle over 500cc)
Categories in target variable ['Fatal', 'Serious', 'Slight']
Histogram [529, 5032, 5010]
We can see that there is one step down between Serious and Slight accidents for Speed_limit(40 50 60) & Vehicle_Type(Motorcycle over 500cc) compared to entire dataset, where only huge steps up appear.
Quantifiers available
Possible quantifier values are
Base - number of records that satisfies condition
RelBase - relative number of records that satisfies condition, Base / Total number of records
S_Up - consecutive steps up in histogram
S_Down - consecutive steps down in histogram
S_Any_Up - total number of steps up in histogram
S_Any_Down - total number of steps down in histogram
Max - maximal value in histogram
Min - minimal value in histogram
RelMax - relative maximal value in histogram (out of sum of all values in histogram)
RelMin - minimal value in histogram (out of sum of all values in histogram)
RelMax_leq - relative maximal value in histogram (out of sum of all values in histogram) - upper bound
RelMin_leq - minimal value in histogram (out of sum of all values in histogram) - upper bound
Note
Most quantifiers are naturally greater or equal, like base, confidence etc. Sometimes, also upper band is needed (like relmax, relmin) - e.g. to have similar histogram values, you can bound min and max values close to avegare.
Therefore, next quantifierq with _leq extesion has been introduced (leq = less or equal).
UIC Miner
Motivation
Basic idea was when you assign task to a human force (like doctors, salesmen, …), they need to feed success at least at a specific level. If you find the way how to sell extremely profitable product with very low probability (e.g. 0.1%) or to discover disease by non-trivial examination, executors (salesmen, doctors) will have doubts because on individual level (salesman, doctor, or even a team), number of successes will be very small. Even if you find the group in which the probability is 5 times higher.
Why? Imagine that salesman can call extra 20 calls per week to his standard work. With success rate, there will be 1 expected success in 5 member team in 2 weeks, they can attribute is to a good luck.
For that reason, it is good to mix up this selection with other, not so rare (and probably less profitable) category. The overall success rate will be much higher and you can achieve the selection with extremely rare and well profitable product will be sold when you go to company level.
We can see in on Accidents dataset. There is a low occurence (e.g. in Accidents dataset, Fatal category has 1.9%). Boosting it 5 times mean to have <10% share. So we may mix this category with Serious (with 19.6% share) and look for circumstances, where overall probability >30% and Fatal is moosted most.
The same situation is in sales, where salesperson has success rate <5% (even on high profitability product), they will be frustrated and will give up. So mixing this category with other with lower profitability but higher occurence could be a good strategy but we need to keep high profitability product with as high share as possible.
This procedure has been created recently when there was typically no rule with steps up in CF-Miner, but raising rare categories may be big business value.
Searched pattern
UIC Miner looks under which circumstances weighted improvement in category occurence is over the specified limit. Improvement is given compared to condition or entire dataset.
Cedents to be defined for SD4ftMiner are * ante - antecedent - histogram for condition ante & cond is evaluated against histogram for condition cond * cond - condition - determines base subset to be compared with
Note
Condition is optional in UIC Miner. If you want to use UIC Miner without condition, simply omit this cedent in procedure call.
Let assume we have target variable with \(k\) categories \(c_1,c_2,\dots,c_k\). You can assign weights (importance) of individual categories - weight vector \([w_1,w_2,\dots,w_k]\) as an input. Then, we will take improvement of probability (occurence) of category i as \(\max\{\frac{P(c_i|ante\&cond)}{P(c_i|ante)},0\}\), which is in fact increase in probability of category \(c_i\) on a subset given by antecedent. The overall improvement aad_score is calculated as \(\sum_{i=1}^{k}\max\{\frac{P(c_i|ante\&cond)}{P(c_i|ante)},0\}\) that measures the level of interestingness of the rule. UIC Miner then support aad_score as a quantifier that filters-out the rules in resultset.
Example of call
As an example, we will use following code
clm = cleverminer(df=df,target='Severity',proc='UICMiner',
quantifiers= {'aad_score':20,'aad_weights':[5,1,0],'base':200},
ante ={
'attributes':[
{'name': 'Driver_Age_Band', 'type': 'seq', 'minlen': 1, 'maxlen': 3},
{'name': 'Driver_IMD', 'type': 'seq', 'minlen': 1, 'maxlen': 3},
{'name': 'Sex', 'type': 'subset', 'minlen': 1, 'maxlen': 1},
{'name': 'Area', 'type': 'subset', 'minlen': 1, 'maxlen': 2},
{'name': 'Journey', 'type': 'subset', 'minlen': 1, 'maxlen': 2},
{'name': 'Road_Type', 'type': 'subset', 'minlen': 1, 'maxlen': 2},
{'name': 'Speed_limit', 'type': 'seq', 'minlen': 1, 'maxlen': 2},
{'name': 'Light', 'type': 'subset', 'minlen': 1, 'maxlen': 2},
{'name': 'Vehicle_Location', 'type': 'subset', 'minlen': 1, 'maxlen': 2},
{'name': 'Vehicle_Type', 'type': 'subset', 'minlen': 1, 'maxlen': 1},
{'name': 'Vehicle_Age', 'type': 'seq', 'minlen': 1, 'maxlen': 11}
], 'minlen':1, 'maxlen':2, 'type':'con'}
)
clm.print_summary()
clm.print_rule(1)
clm.print_rule(17)
Result may look like
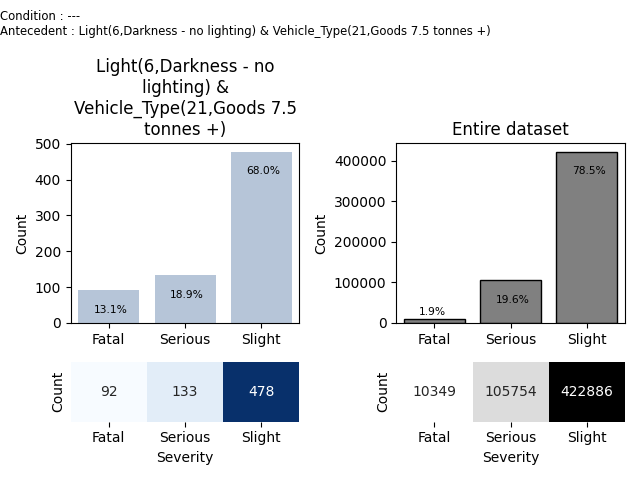
Rule id : 17
Base : 703 Relative base : 0.001 aad score : 29.078778647946276
Condition : ---
Antecedent : Light(6,Darkness - no lighting) & Vehicle_Type(21,Goods 7.5 tonnes +)
Histogram [92, 133, 478]
Histogram on full set with condition [10349, 105754, 422886]
Relative histogram [0.13086770981507823, 0.1891891891891892, 0.6799431009957326]
Relative histogram on full set with condition [0.019200762909818196, 0.19620808587930366, 0.7845911512108782]
Interpretation:
Severity(Fatal) has occurence 1.9%, with antecedent it has occurence 13.1%, that is 6.816 times more.
Severity(Serious) has occurence 19.6%, with antecedent it has occurence 18.9%, that is 0.964 times more.
Severity(Slight) has occurence 78.5%, with antecedent it has occurence 68.0%, that is 0.867 times more.
We can see that Fatal category has occurence 13.1% (6.8x more that in entire dataset) when total occurence of Fatal+Serious raised from 21.5% to 32.0%. The situation is also in the following chart.
Quantifiers available
For quantifiers, available parameters are
aad_weights - weight vector (array) for target variable. Must have the same length as number of categories of target variable.
aad_score - minimum score to include the rule in output.
Base - number of records that satisfies condition
RelBase - relative number of records that satisfies condition, Base / Total number of records
Working with results (API)
If you want to have really machine readable results, you can use dictionary (JSON) that is returned from a CleverMiner call.
print(clm.result)
There are also functions to print list of rules and print individual rule.
clm = cleverminer(df=df,proc='4ftMiner',
quantifiers= {'Base':2000, 'aad':0.4},
ante ={
'attributes':[
{'name': 'Driver_Age_Band', 'type': 'seq', 'minlen': 1, 'maxlen': 3},
{'name': 'Speed_limit', 'type': 'seq', 'minlen': 1, 'maxlen': 2},
{'name': 'Sex', 'type': 'subset', 'minlen': 1, 'maxlen': 1},
], 'minlen':1, 'maxlen':3, 'type':'con'},
succ ={
'attributes':[
{'name': 'Severity', 'type': 'lcut', 'minlen': 1, 'maxlen': 2}
], 'minlen':1, 'maxlen':1 , 'type':'con'}
)
print(clm.result)
clm.print_summary()
clm.print_rulelist()
clm.print_rule(8)
List of API functions
Majority of API functions are available from version 1.1.1
The list of functions to work with results and their detailed characteristics (API for the CleverMiner) are:
print_summary() prints out task processing summary like time elapsed, number of verifications and number of rules found
print_rulelist() prints out simplified list of all rules in human readable format
print_rule(i) prints out details of rule with id i
draw_rule(i, show=True) draws a rule(available from version 1.1.0). When
show=False, it does not show the rule but it is available in Matplotlib so you can either show it byplt.show()or delay showing at the end of processing when multiple tasks are computed (callingplt.show()at the end of script) or save it byplt.savefig("your_image_name.png")get_rulecount() returns number of rules in resultset
get_ruletext(rule_id) returns a string representing a rule rule_id
get_fourfold(rule_id,order=0) returns fourfold table for rule rule_id; for SD4ft-Miner, order parameter is mandatory and possible values are 1 and 2 as there are two fourfold tables as a result in SD4ft-Miner is a couple of rules
get_hist(fule_id,fullCOnd=True) returns histogram for rule rule_id; for UIC Miner, by default histogram for entire set with condition is returned, but histogram rule rule_id with antecedent and condition can be returned if fullCond=False is specified
get_hist_cond(rule_id) returns histogram for rule rule_id on entire dataset given by condition
get_quantifiers(rule_id,order=0) returns all quantifiers for rule rule_id
(marked for removal) get_varlist() returns list of variables in dataset
(marked for removal) get_category_names(varname,varindex) gets list of categories for variable given by name or given by index in variable list (see get_varlist())
print_data_definition() prints summary information how data will be handled (list of variables and number of categories in each variable)
get_rule_cedent_list(rule_id) gets a list of cedents used in a rule rule_id
get_rule_variables(rule_id,cedent,get_names=True) get a list of variables in a rule rule_id in its cedent cedent (get_Names option controls if names or dataset indices of variables are returned)
get_rule_categories(rule_id,cedent,variable,get_names=True) get a list of categories in a rule rule_id in its cedent cedent for variable variable (get_Names option controls if names or dataset indices of categories are returned)
get_dataset_variable_count() gets count of variables in underlying dataset
get_dataset_variable_list() gets list of variables in underlying dataset
get_dataset_variable_name(idx) gets name of variable for a given index idx in underlying dataset
get_dataset_variable_index(varname) gets index of the variable for a given variable name varname in underlying dataset
get_dataset_category_list(variable) gets a category list for a given variable specified by name or index variable in underlying dataset
get_dataset_category_count(variable) gets a number of categories for a given variable specified by name or index variable in underlying dataset
get_dataset_category_name(variable,cat_idx) gets a category name for a given index cat_idx for a given variable specified by name or index variable in underlying dataset
get_dataset_category_index(variable,cat_name) gets a category index for a given name cat_name for a given variable specified by name or index variable in underlying dataset
API compatibility matrix
Currently, following methods are available for individual procedures
Method |
4ft-Miner |
CF-Miner |
SD4ft-Miner |
UIC-Miner |
|---|---|---|---|---|
print_summary |
yes |
yes |
yes |
yes |
print_rulelist |
yes |
yes |
yes |
yes |
print_rule |
yes |
yes |
yes |
yes |
get_rulecount |
yes |
yes |
yes |
yes |
get_ruletext |
yes |
yes |
yes |
yes |
get_fourfold |
yes |
N/A |
yes(2) |
N/A |
get_hist |
N/A |
yes |
N/A |
yes |
get_hist_cond |
N/A |
yes |
N/A |
yes |
get_quantifiers |
yes |
yes |
yes |
yes |
get_varlist |
yes |
yes |
yes |
yes |
get_category_names |
yes |
yes |
yes |
yes |
print_data_definition |
yes |
yes |
yes |
yes |
get_rule_* |
yes |
yes |
yes |
yes |
get_dataset_* |
yes |
yes |
yes |
yes |
Note that methods for splitting rules to attributes and values (beginning with get_rule_) and dataset description methods (beginning with get_dataset_) are available for all procedures.
Advanced use of CleverMiner
You may mine tasks in a loop as well as machine process the results.
For example, the simple algorithm to find rules not by quantifiers but by number of output rules can be simply developed (example of such algorithm can be found at https://link.springer.com/chapter/10.1007/978-3-031-25891-6_10).
Controlling the mining task
This section shows some advanced ways how to use CleverMiner - how to mine rules multiple times on a same dataset and what are the parameters that control the run.
Loading and saving results
Available from version 1.2.0
If you want to save your results for future reuse without re-running the task (rules found, statistics, …), you can use .save(fname) method. This will store output to a file. This file can be later loaded by .load(fname) and all methods for result displaying (print_, get_, draw) are available.
clm = cleverminer(...)
print("SAVING AND LOADING")
clm.save("test.pkl")
clm.load("test.pkl")
clm.print_rulelist()
Available from version 1.2.1 You can also load data from the file directly, you can use
clm = cleverminer(load="filename.pkl")
Caching results
Available from version 1.2.0
Some tasks are CPU-intensive to calculate. If you are embedding them in the workflow and fine-tuning the workflow itself, you don’t need to recompute the task again. Please specify use_cache option (i.e. opts = {‘use_cache’:True}). It automatically saves a result of the task into a cache file and when you re-run exactly the same task again, it scans the cache and when result is available, it loads it from the cache instead of computing it again.
Note
Cached results and data is stored in the system TEMP directory (clm_cache subdirectory of TEMP). Data is stored only once as a separate file to preserve the space when running multiple tasks on a same dataset.
The following aspects need to be considered
tasks and data may occupy a huge amount of space, mainly when large resultsets are stored
dataset is stored also in the TEMP space, so if it contain sensitive data, avoid this option and/or don’t forget to clean up also this directory
A simplified variable input - clm_vars
Available from version 1.2.1
For easy entry, you don;t need to enter each attribute in form {'name': 'Driver_Age_Band', 'type': 'seq', 'minlen': 1, 'maxlen': 3},. If you want to use subsets, you can use clm_vars(list) method instead. As an argument, you can enter a list of variables and definition of cedent is done. In our first example,
it is used the statement ante = clm_vars(['Driver_Age_Band', 'Sex', 'Speed_limit']),. The general call is clm_vars(a,minlen=1,maxlen=3,type='con'). As the first variable, you can have a list of attribute names or statements if some variable need to be a sequence or left/right cut.
The list of simplified statements you can use is:
clm_seq(varname,minlen=1,maxlen=2) generates a statement for a sequence based on the variable name
varnamewith default minimal and maximal number of possible values if not specified directlyclm_lcut(varname,minlen=1,maxlen=2) generates a statement for a left cut based on the variable name
varnamewith default minimal and maximal number of possible values if not specified directlyclm_rcut(varname,minlen=1,maxlen=2) generates a statement for a right cut based on the variable name
varnamewith default minimal and maximal number of possible values if not specified directlyclm_subset(varname,minlen=1,maxlen=1) generates a statement for a subset based on the variable name
varnamewith default minimal and maximal number of possible values if not specified directly
You can also combine these statements, you can use ante=clm_vars([clm_seq('Driver_Age_Band'), clm_seq('Speed_limit'), 'Sex']) that treats Driver_Age_Band and Speed_limit as sequences and Sex as a default subset, all with a default number of values used.
Mining rules multiple times on a same dataset
Due to heavy crunching, CleverMiner as a first step encodes the dataset into internal binary form for fast evaluation of similar queries. This data encoding can be done once and then reused. To do this, following steps to be held
call the CleverMiner class default constructor with df parameter only (or all parameters for first rule mining)
then, rule rule mining can be done via .mine method that have same parameters as constructor but df is ommitted.
Full example follows
clm = cleverminer(df=df)
clm.mine(target='Severity',proc='CFMiner',
quantifiers= {'S_Down':1, 'Base':100},
cond ={
'attributes':[
{'name': 'Driver_Age_Band', 'type': 'seq', 'minlen': 1, 'maxlen': 3},
{'name': 'Driver_IMD', 'type': 'seq', 'minlen': 1, 'maxlen': 3},
{'name': 'Sex', 'type': 'subset', 'minlen': 1, 'maxlen': 1},
{'name': 'Journey', 'type': 'subset', 'minlen': 1, 'maxlen': 1},
{'name': 'Speed_limit', 'type': 'seq', 'minlen': 1, 'maxlen': 3},
{'name': 'Light', 'type': 'subset', 'minlen': 1, 'maxlen': 1},
{'name': 'Vehicle_Type', 'type': 'subset', 'minlen': 1, 'maxlen': 1}
], 'minlen':1, 'maxlen':2, 'type':'con'}
)
clm.print_summary()
clm.print_rulelist()
clm.print_rule(1)
clm.mine(target='Severity',proc='CFMiner',
quantifiers= {'S_Down':1, 'Base':100, 'relmax_leq' : 0.183},
cond ={
'attributes':[
{'name': 'Driver_Age_Band', 'type': 'seq', 'minlen': 1, 'maxlen': 3},
{'name': 'Driver_IMD', 'type': 'seq', 'minlen': 1, 'maxlen': 3},
{'name': 'Sex', 'type': 'subset', 'minlen': 1, 'maxlen': 1},
{'name': 'Journey', 'type': 'subset', 'minlen': 1, 'maxlen': 1},
{'name': 'Speed_limit', 'type': 'seq', 'minlen': 1, 'maxlen': 3},
{'name': 'Light', 'type': 'subset', 'minlen': 1, 'maxlen': 1},
{'name': 'Vehicle_Type', 'type': 'subset', 'minlen': 1, 'maxlen': 1}
], 'minlen':1, 'maxlen':2, 'type':'con'}
)
clm.print_summary()
clm.print_rulelist()
clm.print_rule(1)
Note
You can also run first mining task with default constructor and then use .mine method for another rule mining tasks.
Advanced options (expert use only)
You may use advanced options (use it only when you really know what you are doing).
no_optimizations - switches off optimizations (going to branches where no rule may exists)
max_categories - maximum number of categories allowed in input. Default is 100.
verbose - how many detailed information should be shared (values are FULL, RULES, HINT and DEBUG
max_rules - maximum rules to mine; after achieving mining may be stopped
no_automatic_data_conversions - disable automatic data conversions (automatic data conversions converts data to ordered values if possible with best effort e.g. transforming integer values stored as strings to be sorted as integers and ordering) - from version 1.0.5
keep_df - keep df in object and for referencing - from version 1.0.7
disable_progressbar - disables progressbar (if any issues arised) - from version 1.0.6
Publications with Examples of use
You can find more details how to use this package in following publications
Mechanizing Hypothesis Formation - Principles and Case Studies - foundations of GUHA procedures and examples of use, mainly for extremely advanced former Windows Assembly (LISp-Miner), but principles with advanced Python API remains the same)
GUHA method and Python language - announcement of development advanced asscociation rules (GUHA) that is much advanced than current methods but not generally known in Python
Enchanced Association Rules and Python - example of algorithm that mines association rules not by typical quantifiers like base and confidence but by number of rules that is human absorbable and able to consider
A novel algorithm for mining couples of enhanced association rules based on the number of output couples and its application - parameter free algorithm for mining SD4ft rules
A novel algorithm weighting different importance of classes in enhanced association rules - Introducing UIC-Miner
Disclaimer
Danger
Note that package is under development and function calls and parameter names or structure may change. If you need compatibility, use PRO version.
Danger
Authors take no warranty when using this site or package itself.